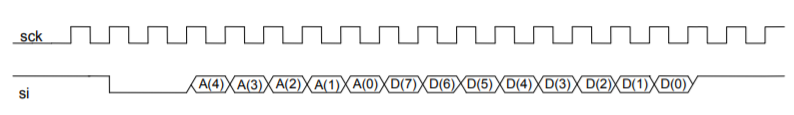tl;dr I found a remote code execution bug in VSCode that can be triggered from
untrusted workspaces. Microsoft fixed it but marked it as moderate severity
and ineligible under their bug bounty program.
Scroll to the proof-of-concept section if you want to skip the details.
Background
Around two months ago, I was researching github.dev,
a lightweight web based editor for Github that uses vscode in the browser. I had
gotten really into Github’s bug bounty program and vscode seemed like a fairly
large attack surface to take a look at. During this time of digging around
github.dev, I decided to take a look at bugs in vscode itself.
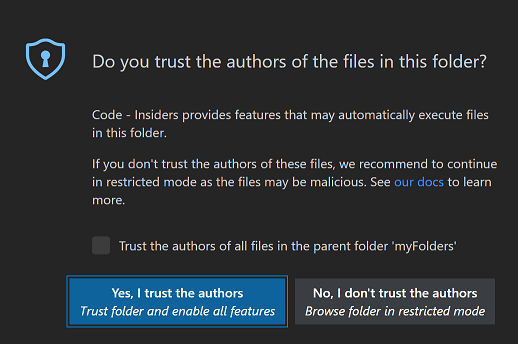
For those unfamiliar, vscode has a feature called Workspace Trust.
When you open a folder, vscode will prompt you asking if you trust the authors
of the files you are viewing. If you say no, vscode goes ahead and disables many
of its features that could allow the workspace to cause automatic code execution.
This includes things like tasks
because an attacker could just make a task that executes a command with the
runOn setting
set to folderOpen. Extensions get disabled unless the authors have explicitly
marked their extension as being able to handle untrusted workspaces.
One other thing that gets disabled is workspace settings. Folders can specify
settings specific to them in a .vscode/settings.json file. Just from looking
in the wild, this can be used to control things like:
However, these settings could potentially be dangerous. Consider for
example, the typescript.npm setting, which controls the location of the npm
executable. This controls an executable path therefore untrusted workspaces shouldn’t
be allowed to set it. Extensions that mark themselves as capable of running
in untrusted workspaces hence have to declare a restrictedConfigurations
field. This controls settings that can’t be set at the workspace level.
This got me to thinking, since vscode itself has built-in settings like
editor.fontFamily, how are those handled in untrusted workspaces?
It turns out, the core of vscode itself uses a .registerConfiguration method
where you have to explicitly pass 'restricted': true in order to make a property
not settable in an untrusted workspace.
Unlike the API for extensions, when vscode needs to retrieve the value of a
setting it generally uses configurationService.getValue('settings.key'). The
settings.key here doesn’t necessarily need to have been declared as part of
registerConfiguration or in an extension’s declared settings. This got me to
perform a search for all uses of configurationService.getValue in vscode and
I found…
The Bug: An undocumented setting
Just like any other tech company, Microsoft loves their A/B experiments and has
chosen to put them in vscode as well.
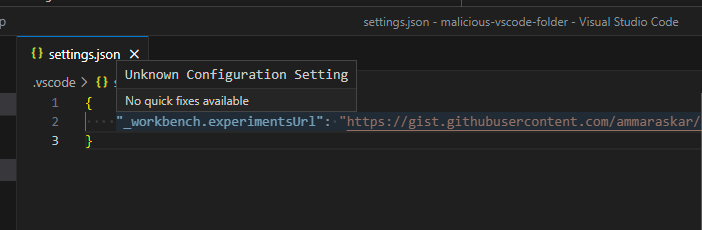
When I was searching for uses of configuration I stumbled upon this line:
This setting controls the url that vscode would fetch experiments from.
Experiments usually need code to run so this seemed like a good avenue. I
declared the setting in a .vsocde/settings.json file and got the following:
Looks like the setting was completely unregistered and hence was not marked as
restricted! This meant that I could set it in an untrusted workspace. It was
time to dive deeper on what vscode experiments could actually do.
I took a look at the default experiments url https://vscodeexperiments.azureedge.net/experiments/vscode-experiments.json
and here is one of the example experiments:
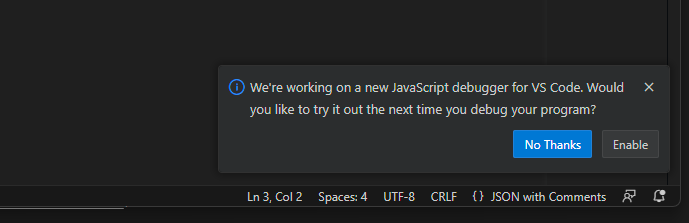
{"id":"copeet.jsDebugNodeInsiderPrompt","enabled":true,"schemaVersion":3,"condition":{"insidersOnly":true,..."activationEvent":{"event":"onDebugResolve:node","minEvents":3}},"action2":{"type":"Prompt","properties":{"promptText":"We're working on a new JavaScript debugger for VS Code. Would you like to try it out the next time you debug your program?","commands":[{"text":"No Thanks"},{"text":"Enable","codeCommand":{"id":"extension.js-debug.experimentEnlist","arguments":[]}}]}}}
This experiment means that if a user is on the insider build of vscode and
debugs node.js more than 3 times, a prompt shows up asking them to enlist in
an experimental javascript debugger.
For reference, this is what it looks like when the experiment prompt shows up:
If they click Enable on the prompt, it issues the extension.js-debug.experimentEnlist
command which presumably the javascript extension has declared and enlists them for the
experiment.
This codeCommand was going to be our vector. codeCommand is a way to execute
commands in vscode,
this includes things like git.stage which asks the git extension to stage a
file.
The attacker fully controls the prompt, its text and what command it
issues. We could now make an official looking prompt show up and when dismissed, make
it run arbitrary code.
Proof-of-Concept
An attacker can host an experiments.json on a website, you can find the one
I used on gist.github.comhere.
They can create a .vscode/settings.json file that contains
and with the experiments file containing a malicious payload such as this:
{"experiments":[{"id":"ammar2.test.experiment14","enabled":true,"schemaVersion":5,"action2":{"type":"Prompt","properties":{"promptText":"[Welcome to VS Code. ...](command:workbench.extensions.installExtension?ms-vscode.hexeditor '.')","commands":[{"text":"Continue","codeCommand":{"id":"workbench.extensions.installExtension","arguments":["ms-vscode.hexeditor"]}}]}}}]}
The interesting things here are that the attacker fully controls the prompt text,
they can make it look like a benign pop-up saying that vscode successfully
updated or anything that will make the user click it.
Since markdown is supported in these pop-ups, they can also make the body of the
text be clickable and perform a vscode command. All buttons are also controlled,
so they could make both a “No Thanks” and “Yes” button both perform the attack.
When the victim opens the folder they are met with an official looking prompt
from vscode like this:
And if they click the body of the text or “Continue”, it installs an attacker
controlled extension.
This is an RCE because an extension in
vscode has full access to the node.js api, it can simply use child_process
to execute commands. An attacker can publish an extension with such
functionality and have it do so at install time.
Additional impact
While remote-code execution after opening a folder in vscode is bad enough, this
gets a lot worse when you consider github.dev
This is a web vscode instance with a fairly generous repo scoped oauth token
preloaded into it automatically by Github. If an attacker gets code-execution on
github.dev, they can steal your oauth token. This lets them read all your repos,
push to them on your behalf, change their settings etc.
May 24, 2023 - MSRC marks the bug as being in the Pre-Release stage.
May 30, 2023 - MSRC marks the bug as ineligible for their bug-bounty, their response is as follows.
Thank you for taking the time to share your report. Based on the assessment from our engineering team, we have determined that your case 78793 is not eligible for an award under the Microsoft Bounty Programs. Your case may still be eligible for earning points under the MSRC Recognition Program.
Your case 78793 was assessed as follows:
Severity: Moderate
Security Impact: Spoofing
Thank you again for your submission! This report was marked as out of scope as the issue was assessed as having a moderate severity impact. Only cases assessed as important or critical are eligible for bounty.
Suffice it to say, this is not the response I wanted to see after they took
2 months to triage a remote code execution bug. A severity of moderate and an
impact of spoofing dumbfounds me and hence I am making this disclosure public.
The impact should be low as a new vscode release should be out on
May 31.
Microsoft security and vscode
I am hardly the first person to be alarmed by Microsoft’s handling of vscode
bugs. I do not know if this is caused by the vscode team not taking security
seriously or poor communication between MSRC and the vscode team but something
clearly needs improvement here.
Back in September 2022, zemnmez from Google also found an RCE
in vscode and Microsoft took 2 months to fix it while also considering it
out of scope for their bug bounty.
This makes sense but for some reason they consider bugs even in first
party extensions that they literally ship in vscode out of scope as well.
Bugs such as
A command injection bug found in the in-built git extension by SonarSource
was considered ineligible by Microsoft.
Another bug I found in the first party Github Repositories extension
that would have allowed an attacker to steal your private repos by just having
you click a link to github.com (I may write a follow-up blog post about this)
In the future, I am going with the public disclosure route for any vscode related
bugs I find. I would encourage other security researchers to do the same until
there is some improvement.
Working with MSRC on any vscode related security bugs has been
dreadful. I hope someone from Microsoft security sees this and explains what
happened and tries to make it right but I am certainly not holding out for it.
This is a rather large blog post consisting of multiple sections from some quick
background information about the problem to an in-depth dive into the hacking
process, reverse engineering and final custom application.
I’ve included a table of contents to make it easy to navigate or if you want
to skip to any parts you’re particularly interested in.
A set of Philips Hue lights that provide light around the room.
The Hue lights are really nice, allowing
you to change up the color and brightness to really change the look of your
environment. You can go from a bright white fluorescent light for studying to a
dim yellow nightlight for midnight lounging.
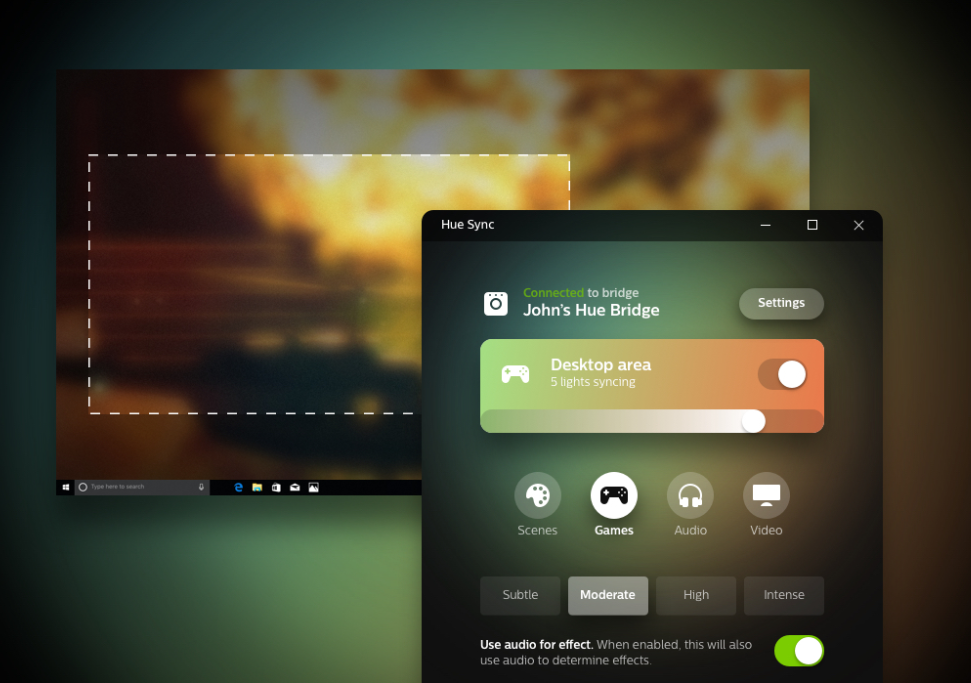
Moreover, Philips semi-recently released a feature called
Hue Entertainment that allows
you to sync up your lights to music, videos etc. This looks absolutely fantastic
and really makes watching movies and playing games a lot more immersive like
this:
A 50-inch Elment 4K TV powered by Roku.
This Element TV
was one of the cheapest at the time and it has held up well over the years.
I don’t actually use any of the Roku/Smart TV functionality on it, instead
the primary sources on it are a Playstation, Xbox and Chromecast.
All of this brings us to the problem, the Hue ecosystem is blissfully unaware of
anything on the TV. The Hues need some sort of software that can read the pixel
values on the screen and set the lights to the right color. On the computer,
this is achieved through the use of the Hue Sync App,
a program that runs in the background capturing your screen and using it to
decide the colors.
However, when it comes to content playing on the TV, there is really no easy way
to pump the pixel data to your controller software. You could mirror your
computer screen with an HDMI cable but that’s doesn’t allow you to capture stuff
like game consoles and requires you to playback all your media on your computer.
If you wanna pay an arm and a leg, Philips has a device called an
HDMI Sync Box.
It costs $230 at the time of writing, almost the price of the actual TV!
The sync box works as a 4-way HDMI switcher, you plug in all your devices like
your Chromecast and consoles into it and then you can select which one to pass
through. It listens in on the video signal and then uses it to match the lights.
Simple enough but stupidly expensive.
On the other hand homebrew solutions for this vary widely. One of the most
promising ones has been using an HDMI splitter that takes the signals and sends
it to two outputs. You plug one into the TV and plug the other into a capture
card hooked up to a Raspberry Pi. The Pi then uses software written by the
Harmonize Project to sync
up the lights.
One solution that I used for a little while was to have a Raspberry Pi hooked
up with a camera looking at the screen. Perform some perspective warping and
then detect the colors on screen with that. This was pretty appealing since it
requires no fuffing about with HDMI cables or splitters. You can find an example
of such code here as part of the PiHueEntertainment project.
You can find my own hacky disgusting code to do the same thing here.
Roku TVs
Alright, now that we know a bit about the problem, let’s talk about Roku
powered TVs.
Roku devices themselves are positively ancient, they came out in 2008 and
predate the creation of Chromecasts, Fire TV sticks, AppleTV etc. They
popularized the lightweight streaming device area, allowing people to watch
Netflix, Youtube, Hulu and friends on their TVs in a super convenient way.
Starting in the mid 2010s, we started seeing the popularization of “smart TVs”.
As opposed to “dumb TVs” that can only display what you plug into them, these
smart TVs started integrating streaming features into the TV itself. This meant
that TVs themselves started being able to connect to the internet and have
enough hardware to stream and decode video.
Roku, realizing they had already built up a software stack and ecosystem in this
area partnered with TV manufacturers to provide Roku as the operating system
for these Smart TVs. This partnership was generally done with low-end
TV makers like TCL, Hisense and my own Element. These companies would generally
not be able to write their own smart TV software unlike the big players:
Samsung, LG, Sony etc.
Now these Roku TVs have one particularly creepy and privacy intrusive “feature.”
The TV will look at the content you’re watching from your HDMI/cable or other
devices and advertise watching them from the beginning on their own smart
services. This Verge article
goes into it in a bit more detail. It shows up on the TV like this:
The presence of this advertising indicates that the TV is capable of monitoring
what is being played through its inputs and encouraged me to start looking for
a way to try to get my own code running on it.
Hacking the Roku
The Roku Developer Ecosystem
Within Roku’s operating system, each streaming service is serviced in the form
of an app which Roku calls a “channel”. These apps/channels can be obtained from
Roku’s marketplace and allow services like Netflix, ESPN, Youtube etc to make
their interfaces and streams available on Roku devices.
As such, Roku has an SDK so that you can developer your own little Roku app.
The process for developing an app is quite open, allowing you to use your own
device as a development environment as long as you know the right button combo
to press. Much like Android where you tap the Build Number button in the
about page to enable developer options, on Roku you enter a Konami-code like
sequence.
Roku’s developer setup
page goes over the details, at the time of writing you just had to press
(Home, Home, Home, Up, Up, Right, Left, Right, Left, Right) to be brought to
the developer settings. Once active, your TV starts up a web server that lets
you upload apps packaged as zip files.
Coding Roku Apps
Great, so this allowed me to run my own apps on the Roku. Now what are these
apps actually programmed in?
As it turns out, Roku has rolled their own programming called BrightScript. And
it is based on, of all things, Basic.
In their own words, BrightScript is an interpreted language running on a C-based
interpreter.
BrightScript compiles code into bytecode that is run by an interpreter. This
compilation step happens every time a script is loaded and run. There is no
separate compile step that results in a binary file being saved. In this way
it is similar to JavaScript.
BrightScript is a powerful bytecode-interpreted scripting language optimized
for embedded devices. In this way it is unique. For example, BrightScript and
the BrightScript component architecture are written in 100% C for speed,
efficiency, and portability.
As anyone who has tried to sandbox a capable language will tell you, it is a
fairly tough job. Correctly restricting things like filesystem access, ensuring
you don’t accidentally expose library functions and the like without support
from the operating system such as with cgroups is very tough. On an embedded
system such isolation was unlikely so BrightScript was likely going to be a good
place to start to find exploits.
BrightScript is fairly powerful, it has bindings for stuff like OpenSSL,
UDP/TCP sockets and JSON parsing. After uploading the hello world app and
having a glance at the developer documentation, I quickly realized there was
actually an interactive REPL for Brightscript
running on a telnet server on the TV.
We can hop onto the Brightscript REPL server with telnet 192.168.1.69 8085
and start exploring:
As it turns out, my TV model, the 7000X is fairly powerful according to
Roku’s specs.
4K Roku TV
Code Name
Longview
roDeviceInfo.GetModel()
7000X
CPU
ARM dual core 1.2 GHz
Accelerated Graphics API
OpenGL ES 2.0
RAM
1 GB
Max UI Resolution
1920X1080
Max Playback Resolution
3840x2160
A Vulnerable API Function
The next step was to explore the API surface and one really interesting aspect
of this was the roUrlTransferobject
which essentially allows you to make http requests. For example:
Where there’s http on embedded devices, curl or
libcurl is usually close behind. The documentation
on the ifUrlTransfer page also confirms this:
EnablePeerVerification(enable as Boolean) as Boolean
Verifies that the certificate has a chain of trust up to a valid root
certificate using CURLOPT_SSL_VERIFYPEER.
One key thing to realize about curl is that even though it is primarily used for
web requests, it supports a wide variety of other protocols
(these can be
disabled during compilation) such as:
ftp:// - File Transfer Protocol
gopher:// - The Gopher Protocol
but most importantly for us, it supports the file:// protocol that lets you
grab files from the local file system. For example on your machine running
Clearly there was some attempt to restrict the file:// protocol, but how
good was this attempt? As it turns out, not really. Roku wanted you to be able
to use file:// to access files that you could access through the normal file
APIs they provide, so for exmaple you can do:
exposing some nice internal paths to us. But this also shows that they seem to
be concatening our url path in front of tmp/plugin/GPAAAAX4Lckh/ so could
we just use the ../.. characters in the URL to traverse up the path?
Not quite, looks like there’s some magic going on that strips out the dot dots
out of the url. However, there seems to be one simple trick that the Roku
developers forgot about. URLs support url/percent encoding,
so instead of putting in the raw .. we can replace it with the equivelant
percent encoded characters, %2E%2E. This gives us the url:
So at this point we have the ability to read files from the system, but what
does this really give us? Well Linux is awesome and exposes a lot of critical
information through procfs usually
present under /proc/ on the system.
For example, the file /proc/self/environ will tell you the environment
variables the file-reading process was launched with:
Among other things, procfs also exposes the memory map of a process, e.g what
memory addresses parts of the executable, shared libraries, the stack and heap
are present at. This is usually found at /proc/self/maps.
procfs can also tell you what filesystems are mounted on the system through
/proc/mounts.
Both of these were absolutely valuable in performing reconnaissance and
understanding how Roku had set up their Linux distribution. For example through
/proc/version we can learn what kernel the Roku is using:
Linux version 3.10.108-grsec-rt122 ([email protected])
(gcc version 5.4.0 (crosstool-NG crosstool-ng-1.22.0 - Roku GCC toolchain 20191226))
#1 SMP PREEMPT Thu Jul 16 21:50:19 UTC 2020
Through /proc/self/maps we learn that the main Roku application that runs
on the TV lives under /bin/Application and it utilizes a ton of shared
libraries:
Through this information we can acquire the application binary as well as the
key libraries and pop them open in ghidra to understand how they work. As it
turns out the Roku software stack is a gaint C++ application. As someone who is
primarily used to reverse-engineering C this presented a bit of a learning curve
but once you figure out the usual suspects like std::string and std::vector,
it becomes a lot easier. It also helped that the system uses lots of shared
libraries so there are a lot of exported symbol names present.
Grabbing binary files was a little more complex than simple text files, this is
because BrightScript strings are null terminated and thus the r.GetToString()
function would only return results up to the first null byte, making it useless
for ELFs and other binaries. We ended up finding a work-around by saving the
data to a file with r.GetToFile("tmp:/file_to_save") and then streaming it
over the network in chunks that could be held in memory or saving it to a USB
drive using r.GetToFile("ext1:/file").
At this point, I realized that my method of downloading one file at a time was
fairly limited and only gave me a fairly narrow view on what was on the system.
So we took a look at /proc/cmdline:
specifically. We realized that rootfs is loaded from /dev/mtdblock_robbs1 and
is cramfs based. So at this point we decided to download the entire
/dev/mtdblock_robbs1 device and take a look at it. Running binwalk on it we
find:
$ binwalk mtdblock_robbs1.cramfs
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
0 0x0 Roku aimage SB
512 0x200 Squashfs filesystem, little endian, version 4.0, compression:gzip, size: 63975146 bytes, 3615 inodes, blocksize: 131072 bytes, created: 2020-12-04 05:06:22
63979520 0x3D04000 Roku aimage SB
64245760 0x3D45000 Roku aimage SB
64293472 0x3D50A60 AES S-Box
64296384 0x3D515C0 AES Inverse S-Box
64491980 0x3D811CC Roku aimage SB
64512364 0x3D8616C SHA256 hash constants, little endian
65266848 0x3E3E4A0 CRC32 polynomial table, little endian
65267872 0x3E3E8A0 CRC32 polynomial table, little endian
65433083 0x3E66DFB mcrypt 2.2 encrypted data, algorithm: blowfish-448, mode: CBC, keymode: 8bit
66324957 0x3F409DD Cisco IOS experimental microcode, for "O"
69996544 0x42C1000 Roku aimage SB
69996800 0x42C1100 uImage header, header size: 64 bytes, header CRC: 0x2B984F0E, created: 2020-12-04 05:06:45, image size: 3409876 bytes, Data Address: 0x21C08000, Entry Point: 0x21C08000, data CRC: 0x64F1A541, OS: Linux, CPU: ARM, image type: OS Kernel Image, compression type: gzip, image name: "Linux 3.10.40"
69996864 0x42C1140 gzip compressed data, maximum compression, has original file name: "vmlinux.bin", from Unix, last modified: 2020-12-04 05:06:44
73420800 0x4605000 Roku aimage SB
Awesome, it’s in an intact squashfs filesystem and a bunch of extra stuff tacked
on at the end. Having binwalk extract out the squashfs we find:
$ ls disk_image
bin config dev home lib media nvram opt proc root sdcard0 sys usr www
common custom etc init linuxrc mnt omv plugins RokuOS sbin sdcard1 tmp var
This made it significantly easier to understand the overall structure of the
system and find exploits in more than just the main application binary.
Getting More Access
While we could read files and understand the behavior of the system pretty
thoroughly, we were still pretty far from code execution. At this
point I met a couple of really smart hackers on the Exploiteers discord,
devnull and popeax who helped a lot by sharing
information and tricks they had discovered.
We were able to discover an undocumented feature in /bin/Application that
Roku had implemented to make the development process a lot easier. Instead of
constantly re-uploading a .zip file to test your channel, they allowed
running a channel through from a Network File System (NFS)
mount. NFS basically allows you to mount directories from other servers over a
network connection. You could utilize this feature by adding the key
pkg_nfs_mount like so:
pkg_nfs_mount=192.168.1.10:/nfs/mnt/path
to your channel manifest. Upon seeing this in the manifest, the channel loader
will try to mount the NFS server and directory you specified and then read the
source files from there.
The key thing to realize about an NFS mount is that it supports all the features
of a Linux filesystem, including the ability to have symlinks. So for example
if on your NFS server you have a symlink set up pointing to / like so:
Importantly, this symlink is resolved on the end of whoever mounted it, so
accessing the file /tmp/test-mount/root/etc/passwd will actually lead to the
/etc/passwd file on the nfs-client system.
Now the implications for this in terms of BrightScript access are absolutely
huge, while we could only read files with the curl based exploit, this actually
lets us write to arbitrary locations in the filesystem too. Ordinarily the
BrightScript filesystem restricts you to locations such as pkg:/, tmp:/,
ext1:/ etc and has robust protection against traversal, a symlink such as the
one from the method above is not detected.
This means that we can now use BrightScript methods such as WriteAsciiFile to
write to anywhere on the filesystem. For example:
and this actually shows up on the Roku under /tmp/test.
Great so through some reverse engineering and a little help from our friends
we’ve turned our arbitrary read into an arbitrary read-write.
Code Execution from Writing Files
Despite being able to write to anywhere, we are still fairly limited. The actual
filesystem is mounted as read-only for almost all directories. This means that
getting code execution won’t be as simple as replacing /bin/Application or
anything like that.
In particular, the only directories that were writable were /tmp and /nvram.
/tmp is as it would be on a conventional Linux system, a temporary file
system. /nvram is a non-volatile storage location that stores data such as the
channels installed by the user, channel specific login information and system
settings and preferences.
Would it be possible to get code execution from writing into one of these
directories? At first glance it seemed fairly difficult, while a lot of init
scripts will execute stuff stored in /nvram, for example S56sound:
#!/bin/sh# Dev mode local overrideread roku_dev_mode rest < /proc/cmdline
if["$roku_dev_mode"='dev=1']&&[-f /nvram/S86sound ]then
echo"=== ALSA INIT from /nvram/S86sound"source /nvram/S86sound
else
modprobe mhal-alsa-audio ||echo"WARNING: ALSA driver not found or failed to load"fi
these are guarded by "$roku_dev_mode" = 'dev=1' checks which is a parameter
set in /proc/cmdline (the Linux startup parameters) for Roku development
machines.
Eventually after searching all across the application and system scripts in the
disk image we stumbled upon the following code as part of the S64wifi init
script:
Let’s take a minute to examine what this is doing.
Set UDHCPD_CONF to default to /lib/wlan/realtek/udhcpd-p2p.conf.
If /nvram/udhcpd-p2p.conf exists, override UDHCPD_CONF with that file.
Copy the UDHCPD_CONF file to /tmp/udhcpd-p2p.conf.
Start up udhcpd
(A light-weight DHCP
server part of busybox)
using the configuration file in /tmp/udhcpd-p2p.conf.
This means that we fully control all configuration parameters to udhcpd if we
set up our own /nvram/udhcpd-p2p.conf file, which the arbitrary file write
exploit allows us to do.
Despite busybox’s reputation of being lightweight, you can expect that any
daemon will have a fun set of options and udhpcd is no exception. It provides
this absolutely fantastic option called notify_file which is described as:
Everytime udhcpd writes a leases file, the below script will be called.
Useful for writing the lease file to flash every few hours.
#notify_file #default: (no script)
And there we have it, as soon as udhcpd hands out a lease, it will invoke the
notify_file we specified. As a cherry on top, udhcpd runs as root as part of
the startup process, so whatever script we provide it will run as root.
For those curious, the Roku has a dhcp server because it supports connecting
certain remotes and devices over a Wi-Fi Direct network.
While I initially ended up connecting my phone to trigger a lease to be handed
out, we also realized that turning auto_time to a very tiny interval will also
cause notify_file to be invoked and this allows the root to be persistent
across restarts without any human intervention.
With this in hand, we set up a script file containing
point notify_file towards it and as soon as a lease is handed out we have a
root telnet server on port 1337:
$ telnet 192.168.1.69 1337
Trying 192.168.1.69...
Connected to 192.168.1.69.
Escape character is '^]'.
WIFI DRIVER PATH: /lib/wlan/realtek
longview:/ # whoami
root
(You can read more about how this process was made slicker by popeax
here)
From Code Execution to Ambient Lighting
Reverse Engineering the TV’s Recognition
Alright so that was a whole adventure to get code execution going, now we can
finally get to the problem that kicked this all off. Getting the TV to control
the lights based on the content it is showing.
So back to the creepy feature I talked about in the introduction, in Roku and
industry speak it is known as “Automatic Content Recognition” (ACR), Roku
themselves describe it as:
The Roku TV is also equipped with Automatic Content Recognition (ACR)
technology that, when enabled, allows Roku to recognize the programs and
commercials being viewed through the Roku TV’s antenna, and devices connected
to your Roku TV, including cable and satellite set top boxes.
so searching for symbols related to “ACR” in the reverse engineered codebase
was a good place to start.
One of the symbols we find is gnsdk_acr_query_write_video_frame. For those
wondering, it looks like Roku uses Gracenote’s ACR library,
hence the gnsdk.
If we look at the caller of the function, it comes with the following logging
calls:
Roku::Log::Logger::log(s_acr.gn._00ca3837,"thrd.exit.early.nullptr","Could not create VideoCapture device");Roku::Log::Logger::logTrace(s_acr.gn._00ca3837,"cap.toosmall","captured frame too small, width %d",iVar3);Roku::Log::Logger::logTrace(s_acr.gn._00ca3837,"thrd.pause","Capture loop is paused");
This is definitely all stuff related to capturing the output of the screen,
putting us on the right track.
In particular the "Could not create VideoCapture device" logging call is very
interesting, it is present under the following context:
av_instance=Roku::PlatformAV::GetInstance();videoCaptureDevice=(av_instance->vtable+0x24)(av_instance);if((int)videoCaptureDevice==0){Roku::Log::Logger::log(s_acr.gn._00ca3837,"thrd.exit.early.nullptr","Could not create VideoCapture device");}
meaning the code we are after is going to be under the PlatformAV class, and
specifically as part of one of the methods it implemenets. Following this chain
of code down to the VideoCapture class and doing some reverse engineering we
find that it does the following:
This was an absolute pain to reverse, but once done led exactly to the critical
library in the capturing process. These CreateDataBuffer and
CreateImageProvider functions are provided by a library called
DirectFB (Direct Frame Buffer) which
is what Roku uses to draw to the TV.
Thanks to DirectFB being licensed under the LGPL, Roku releases their
modifications as part of their OpenSourceSoftware dropbox. So I grabbed
Roku Open Source Software > 9.4.0 > OSS-RokuHDRTV > sources > directfb-1.4.2
and started taking a look.
Writing our own Screen Capture Code
The directfb source code provided by Roku was an absolute treasure trove of
information. As it turns out the Roku TV uses a chip by
MStar Semiconductors that is responsible for
dealing with all the HDMI functionality of the TV. This includes decoding the
HDCP DRM system, switching inputs etc.
As part of the directfb source provided by Roku are examples provided by MStar,
which demonstrate exactly how to use the MStar’s capturing API. In particular,
the "GOPC" stuff we saw in the Roku code above corresponds to a DirectFB
image provider that utilizes the MStar GOP API to capture the image on screen.
I’m not sure what GOP stands for here, if anyone does please let me know.
This capture device uses pretty low-level MStar APIs internally, e.g
MApi_GOP_DWIN_Init() and MApi_GOP_SetClkForCapture() to provide a high
level API to capture the screen. From what I can tell the MStar chip performs
a Direct Memory Access (DMA) into the memory of the Roku to place the image into
it. Either way, the low level details aren’t too important, what we can take
away from this is that we should be able to write our own DirectFB code and
capture the screen.
Thus I set up a development environment on my Raspberry Pi so I could compile
for ARM and hacked away. Luckily the Makefile in the directfb sources that
Roku provide told me exactly how to compile my program:
With that I was blisfully met with a test-00000.bmp that contained:
A perfect little 4K screenshot of the episode of “Halt and Catch Fire” being
played on the TV 🙏
Getting the Lights to React to the Captured Video
With the image in hand, the final piece of the puzzle is getting the lights to
actually change with the content on the screen. This part is relatively easy
though hard to do in a performant way. My initial prototype captured the entire
screen and beamed it over to my laptop so I could display it full screen there
and just use the regular Hue Sync
application to test out.
This certainly worked but it was truly slow, sending a raw 4K image across a
local network from the device ran at around 1-2 frames per second. This was far
too slow. While I could have tried using a JPG encoder to make a much smaller
iamge, I figured that it would be a bit too slow to handle too.
The solution I ended up with for now was to capture the corners of the screen
for a faster capture time, average the pixel values on the device for the corners
and then send those over. This roughtly ended up looking like this:
voidcompute_average_pixel_value(YCbCrColor*average,intpitch,intheight,unsignedchar*data,intx,inty){YCbCrColortotal={0};data+=(y*pitch);for(intj=0;j<EDGE_WIDTH;j++){// Each data_u32 represents 2 pixels.constu32*data_u32=(u32*)data;for(inti=x/2;i<(x/2)+EDGE_WIDTH/2;i++){total.y+=data_u32[i]&0xFF;total.cr+=((data_u32[i]>>8)&0xFF)*2;total.y+=(data_u32[i]>>16)&0xFF;total.cb+=((data_u32[i]>>24)&0xFF)*2;}data+=pitch;}average->y=total.y/(EDGE_WIDTH*EDGE_WIDTH);average->cr=total.cr/(EDGE_WIDTH*EDGE_WIDTH);average->cb=total.cb/(EDGE_WIDTH*EDGE_WIDTH);}voidperform_capture(CaptureStruct*cap){cap->imageProvider->RenderTo(cap->imageProvider,cap->surface,NULL);void*data;intdata_pitch;cap->surface->Lock(cap->surface,DSLF_READ,&data,&data_pitch);compute_average_pixel_value(&top_left_color,data_pitch,cap->height,data,0,0);cap->surface->Unlock(cap->surface);}
The only hiccup here was figuring out the exact YCbCr color encoding that
the MStar uses, but that was again conveniently provided by the directfb source
code.
Currently the code sends these averaged YCbCr colors of each corner to my laptop
which then shows them the full-screen as a set of boxes for the Hue app to pick
up:
After I clean up the code, I will open source it. In the future I’m hoping to
integrate it directly with the Hue entertainment API so it can control the
lights directly but for now, enjoy this demo. It runs at a stable 20-30 fps now
so the effect looks great:
iClickers are used in a lot of colleges in order to conduct quizzes and take
attendance. The whole ecosystem operates as follows:
Each student buys an iClicker device.
They’ve got some buttons on them to respond to multiple choice questions.
They enter the unique ID on the back of the device into their school
database.
Each class is equipped with a base station that connects to the
instructor’s computer via USB.
With iClicker’s software, they can
conduct quizzes and export the answers for automatic grading.
State of the art of iClicker reverse engineering
A significant amount of work has been done as far as figuring out how the
student owned remotes work. The seminal work in this area is contained in this
fantastic paper
conducted by some students at the University of British Columbia where they
dumped out the firmware of the remote. Some key contributions they made were
figuring out the exact radio transceiver used in the device as well as the
obfuscation scheme used in the transmission of the IDs.
Following up to this, some students at Cornell started off a project called
iSkipper where they attempted to create
an open source alternative to the iClicker. By using logic analyzers and
dumping out the raw communications using a software defined radio, they were
able to piece together the protocol that the remotes use to send their answers
over the air. They wrote their own implementation of an iClicker that can be
run on an Arduino with just a 900MHz radio transceiver.
While the iSkipper project has managed to figure out most of the iClicker
protocol, one missing piece is the communication from the base station back
to the remotes. Upon pressing a button, the base station sends back an
acknowledgement packet to indicate that the answer has been accepted. In
addition, the base station can also send a welcome message to the remotes to
indicate what class is currently in progress.
In order to figure out this last missing piece of the iClicker puzzle, I set
out to reverse engineer the receiver.
Acquiring the firmware
The first part of reverse engineering the base station would be to obtain
the firmware that runs on it. Since I didn’t own a base station and didn’t
want to buy one (you can get them for anywhere between $50-$100 on eBay), I
had to figure out an alternative approach to acquiring the firmware.
Searching for iClicker base station firmware led me to the “iClicker Base
Firmware Utility” on the iClicker downloads page.
This software claimed to be able to update the firmware on a base station so
it seemed like a natural target. I initially guessed that they would package the
updated firmware with the executable but searching around in the distributed
files I couldn’t locate any firmware files. Next up I ended up starting the
executable.
“Check for Update”, interesting. This was a massive hint that the updates
were most likely downloaded over the internet. Thus, I cracked open the
executable in IDA and searched away for interesting URLs.
and with that, I had the firmware on my hands without having to install a JTAG
interface or an AVR programmer into a base station.
Reverse engineering the firmware
Alright so next up we gotta disassemble the firmware. I strongly suspected that
there was some Atmel chip inside the base station, just like the remote. Atmel
makes some very popular programmable microcontrollers, a lot of embedded
systems, IoT devices and the Arduino platform use Atmel chips.
Luckily IDA supports disassembling AVR, the architecture used by these
microcontrollers. So I cracked the firmware open in IDA and went to hunt down
the code that generates the acknowledgement packets.
Take the next section with a heavy grain of salt, this was my first time
reverse engineering embedded software and it was very much new and uncharted
territory for me. If I made any glaring mistakes, please feel free to reach out
and I’ll try to amend them :)
ID Decoding
There was a lot of code and I wasn’t exactly familiar with AVR so in order to
get my bearings, I set out to find a known piece of the protocol: the scrambling
and de-scrambling routine for the iClicker remote ID. The iSkipper project had
already figured out the algorithm
to do this:
So a good place to start would be finding functions that do a lot of bit shifting.
Searching for “lsr” (Logical Shift Right), I found a peculiar function:
loc_375a:lsrr30lsrr30lsrr30ret
In AVR, the lsr opcode shifts its argument register right by 1 bit, this looked
an awful lot like the initial part of the decoding algorithm so I followed to
the callers of this right_shift_3 function.
There were some cool tricks that the compiler used in this area, for example in
order to shift right by 7, it didn’t emit 7 lsr instructions. Instead, the
sequence of instructions was
swapr30andir30,0xFlsrr30lsrr30lsrr30
The swap instruction swaps the two nibbles of the byte, so the higher order
4 bites get swapped with the lower order 4 bits. Performing an and with 0xF = 0b1111
after this essentially does the same thing as shifting right by 4.
While this approach led me to the function that decodes the ID, the rest of the
calling logic was not particularly easy to follow. I needed to find more
landmarks in the code to figure out what was going on.
Radio SPI Interface
As mentioned in the introduction, previous reverse-engineers had already
figured out what radio chip was used in the clicker, namely the Semtech XE1203F.
Consulting the datasheets for the IC, we can see that it uses a 3-wire SPI
(Serial Peripheral Interface) based protocol in order to configure the radio
chip. The next logical step was to look at an SPI tutorial for AVR microcontrollers,
I found a great one here with
the following code sample:
SPI_Send:ldir16,0xAAoutSPDR,r16; Initiate data transfer. Wait:sbisSPSR,SPIF; Wait for transmission to complete.rjmpWaitinSPDR,r16; The received data is placed in r16.
Perfect, so we have to look up usages of the SPDR register within the
firmware. There is only one place that used this register, so I labelled the
function as read_write_from_SPI. It reads one argument stored at (Y+1) and
then writes it out the SPI port.
ROM:1393read_write_from_SPI:; CODE XREF: read_write_two_bytes_SPIROM:1393st-Y,r16; Spill register r16ROM:1394cli; Disable interruptsROM:1395lddr30,Y+1ROM:1396outSPDR,r30; SPI Data RegisterROM:1397ROM:1397loc_1397:; CODE XREF: read_write_from_SPI+7ROM:1397inr30,SPSR; SPI Status RegisterROM:1398andir30,0x80ROM:1399cpir30,0x80ROM:139Abrneloc_1397
Here is one of the usages of the SPI writing function:
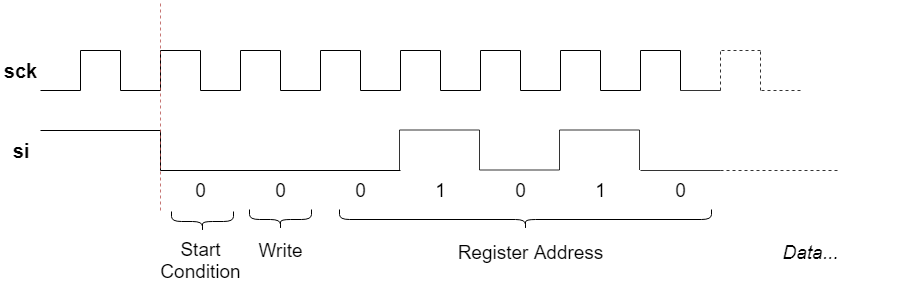
Now if we consult with the XE1203F’s documentation, it mentions the following:
The timing diagram of a write sequence is illustrated in Figure 12 below. The
sequence is initiated when a Start condition is detected, defined by the SI
signal being set to “0” during one period of SCK. The next bit is a read/write
(R/W) bit which should be “0” to indicate a write operation. The next 5 bits
contain the address of the configuration/status registers A[4:0] to be
accessed, MSB first (see 5.2). Then, the next 8 bits contain the data to
be written into the register. The sequence ends with 2 stop bits set to “1”.
Okay cool, now if we take a closer look at the bytes being written out on the
SPI interface as binary, we see the following:
0x8A 0xF
1000 1010 0000 1111
Compare this against the timing diagram from the datasheet above, looks fairly
similar! If we plot it out and label the bits, we see the following:
Great, so this is code that is writing a value to a configuration register in
the radio chip. Notably it’s writing the value 0xF to the register at
address 0x01010. I confirmed this theory by decoding a few more SPI writes.
Register
Value
Description
0x01010
0x0F
Frequency Adjustment MSB
0x01011
0xA0
Frequency Adjustment LSB
0x00010
0x1F
Frequency Band 902–928 MHz
Following the formula in the datasheet, we can see that the frequency will
be the base frequency plus 500 times the frequency adjustment registers
interpreted as a 16 bit two’s compliment number.
Frequency Base = 915 Mhz
Frequency Adjustment = 0x0FA0 = 4000
Final Frequency = (915 Mhz) + (4000 * 500 Hz)
= 917 Mhz
and if we check this against the first paper linked above, we can confirm that
they experimentally figured out the default AA channel operates at 917.0 MHz.
Great, this discovery lets us figure out exactly what parameters the radio
module is using and helped find the portion of the code responsible for changing
frequencies.
Radio Data IO
So the SPI protocol is how the radio module is configured, but looking at the
data sheet we can see that there is a separate DATAIN and DATA port used to
read and write actual radio packets. My first intuition was that the firmware might
be making use of the AVR USART (Universal Synchronous/Asynchronous Receiver/Transmitter)
feature to exchange data with the radio chip.
However, after looking at the interrupt handlers for USART_RXC and USART_TXC
which correspond to when a byte is sent or received by the USART module, it
seemed clear that this is actually how the base station communicates with the
instructor’s computer and NOT where radio messages were read/sent.
Within AVR, IO is primarily done using the in and out instructions. The only
interesting traces I could find for the in instruction was in the INT1
interrupt handler which corresponds to a configurable external interrupt handler.
The following is psuedo-C like code that corresponds to the handler:
And bingo, now that we know where radio_bytes array is in memory, we can
look at cross references to it to find the code that processes packets sent
over the radio.
Dynamic analysis
After a large portion of just statically analyzing the disassembled code, I
decided to use the fantastic avrsim
project that allows you to run avr binaries and even attach gdb to it.
I took the example code in examples/board_simduino/simduino.c and
customized it to my needs. The first most obvious change to make is to change
the MMCU to atmega16.
Next up was setting the appropriate bit and raising the external interrupts to
emulate the radio module receiving bytes.
voidsend_byte(unsignedcharb,avr_irq_t*radio_in,avr_extint_t*extint,avr_t*avr){for(inti=7;i>=0;i--){for(intj=0;j<200000;j++){avr_run(avr);}intbit=(b>>i)&1;printf("Writing bit %d\n",bit);avr_raise_irq(radio_in,bit);avr_raise_interrupt(avr,&extint->eint[1].vector);}}intmain(intargc,char**argv){...intinterrupted=0;while(1){intstate=avr_run(avr);if(state==cpu_Done||state==cpu_Crashed){break;}// divide by 2 to get "word" addresses like IDA usesunsignedintcurr_pc=avr->pc/2;if(curr_pc==0x18E&&!interrupted){// Perform an INT0 interruptavr_raise_interrupt(avr,&extint->eint[0].vector);printf("Raising AVR INT0 interrupt\n");// Raw ID = 0xA2 0x46 0x53 0xB7// My encoded ID = 0x14 0x8C 0x29 0x70send_byte(0x14,radio_in,extint,avr);send_byte(0x8C,radio_in,extint,avr);send_byte(0x29,radio_in,extint,avr);// Sending an answer of 'B' (0x05)unsignedcharlast_id=0x70;last_id&=0xF0;last_id|=0x05;send_byte(last_id,radio_in,extint,avr);// compute the checksumunsignedcharchecksum=0x14+0x8C+0x29+last_id;send_byte(checksum,radio_in,extint,avr);interrupted=1;}}}
Protocol Findings
Hopefully the last section gives you some insight on what the reverse
engineering process was like, not too harp on it too much, let’s move on to
the actual findings in terms of the radio protocol:
Welcome ping packet
The base station sends out this packet on regular intervals (every few seconds),
it contains the welcome message as shown on the iClicker like this:
as well as the question mode being used, which can either be the standard
A/B/C/D/E multiple choice mode, numeric alphanumeric or a sequence of questions.
As mentioned earlier, the welcome message isn’t a normal encoding like ASCII, it
seems custom rolled.
1 to 9 are from 0x81 to 0x89.
0 is represented by 0x8A.
A starts at 0x8B and goes up sequentially like ASCII.
- is 0xA5.
+ is 0xA6.
= is 0xA7.
? is 0xA8.
_ is 0xA9.
Any other bytes will show a blank.
Multiple choice answer ACK packet
Sent to acknowledge an answer for a multiple choice question. These involve
calculations on the encoded iClicker id, which I will refer to as an array
called encodedId.
Accepted
(Shows a tick on the iClicker screen)
Bytes
Description
0-2
Fixed header (Radio sync bytes) 0x55 0x55 0x55
3
Byte 0 of the encoded iClicker ID (encodedId[0])
4
Byte 1 of the encoded iClicker ID (encodedId[1])
5
Bitwise negation of byte 2 of the ID (~encodedId[2])
6
(encodedId[3] & 0xF0) | 0x02
7
Constant 0x22
Closed
(Shows closed on the iClicker screen)
Bytes
Description
0-2
Fixed header (Radio sync bytes) 0x55 0x55 0x55
3
Byte 0 of the encoded iClicker ID (encodedId[0])
4
Byte 1 of the encoded iClicker ID (encodedId[1])
5
Bitwise negation of byte 2 of the ID (~encodedId[2])
6
(encodedId[3] & 0xF0) | 0x06
7
Constant 0x66
Example
My iClicker ID is A24653B7, which encodes to 0x14 0x8C 0x29 0x75 when
answering B.
Let’s calculate the bitwise negation of my encodedId[2]:
0x29 = 0b00101001
~= 0b11010110 = 0xD6
Thus, a positive acknowledgement packet for this answer would be:
0x55 0x55 0x55 0x14 0x8C 0xD6 0x72 0x22
And a negative acknowledgement packet would be:
0x55 0x55 0x55 0x14 0x8C 0xD6 0x76 0x66
Side note: I haven’t documented the ACK packets for other question
modes since I figured there’s not a lot of interest for those, please
let me know if you’d like to see those.
Conclusion
This was my first real project reverse engineering a large real-world project,
especially so in the embedded space. Compared to reverse engineering x86 a
bigger chunk of time was spent reading datasheets for the hardware components,
especially the Atmel processor. The lack of strings, system calls etc also make
it a lot harder to orient yourself and find your way around the code.
I’ve posted my IDA database and a text dump of the firmware on Github.
Feel free to reach out to me if you have any questions.
Deep on the web, I discovered a secret key validation. It appeared to be from
the future, and it only had one sentence: “Risk speed for security”. Something
seems fishy, you should try to break the key and find the secret inside!
Initially we tried using demovfuscator
but all this really did was turn a few movs into leas but nothing too
useful.
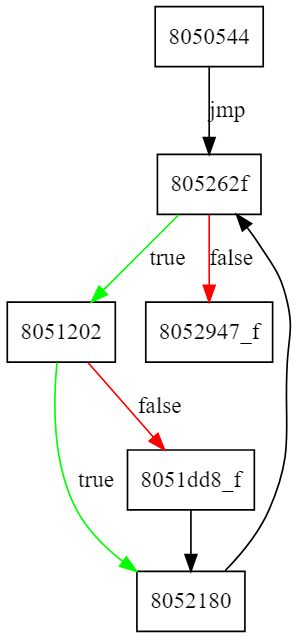
Instead, we used demovfuscator’s -g option to generate the control flow
graph of the program which looked like this:
Since the program was exiting on a wrong input, I decided to experiment by
adding a breakpoint at the first branch and take a look around in gdb. This
breakpoint was being hit thousands of times so I used ignore <bp> 1000000 to
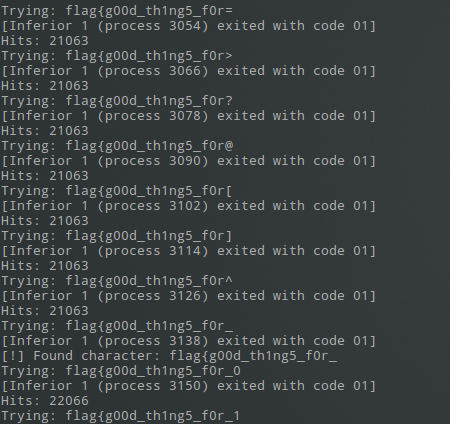
quickly check how many times which resulted in a really interesting output:
flag{
[Inferior 1 (process 24054) exited with code 01]
pwndbg> i breakpoints
Num Type Disp Enb Address What
2 breakpoint keep y 0x0805262f <main+8901>
breakpoint already hit 6018 times
fla__
[Inferior 1 (process 24082) exited with code 01]
pwndbg> i breakpoint
Num Type Disp Enb Address What
3 breakpoint keep y 0x0805262f <main+8901>
breakpoint already hit 4012 times
Notice that when correct input is provided, the breakpoint is hit more often.
Now that we have an indicator to know that one character of input is correct,
we can go ahead and exploit this to recover the flag.
(Note: handle SIGSEGV nostop noprint pass and
handle SIGILL nostop noprint pass are required to debug in gdb since
movfuscator uses signal handlers on SIGSEGV and SIGILL for function calls and
loops)
Exploiting the side channel
We whipped up a quick gdb script to automate the process of monitoring the
breakpoints:
Ever since their hella successful ICO, the crypto experts at VapeCoinIO have
put developers first with their simple, intuitive, and, most importantly,
secure API. Once you’ve created your account and set up your wallet, you can
access it programmatically using your VapeID by sending a GET request to
/api/login?key=<HASH> where <HASH> is your VapeID. Your wallet is
transferred to you over TLS, so don’t worry—it’s really, really secure. In
fact, it’s so secure that the founder and CEO of VapeCoinIO uses the API for his
personal Brainwallet.
One of your contacts is a site-reliability engineer at VapeCoinIO. He has
obtained a PCAP of a TLS session with a client originating from an IP he
suspects to be used by CEO’s personal laptop. Perhaps he accessed his wallet!
Can you find a way to recover its contents?
As the problem description says, the first thing we notice in the PCAP is that
the data is transferred exclusively over a TLS connection. Thus the first thing
we need to look for is something amiss in the TLS exchange such as the use of a
weak cipher.
We can see in the PCAP that the TLS connection is using:
TLS_DHE_RSA_WITH_AES_128_GCM_SHA256
DHE stands for “Diffie-Hellman ephemeral” which is where the RSA key is used to
sign the server’s Diffie-Hellman public number to provide authenticity and
every TLS session uses a new set of public numbers.
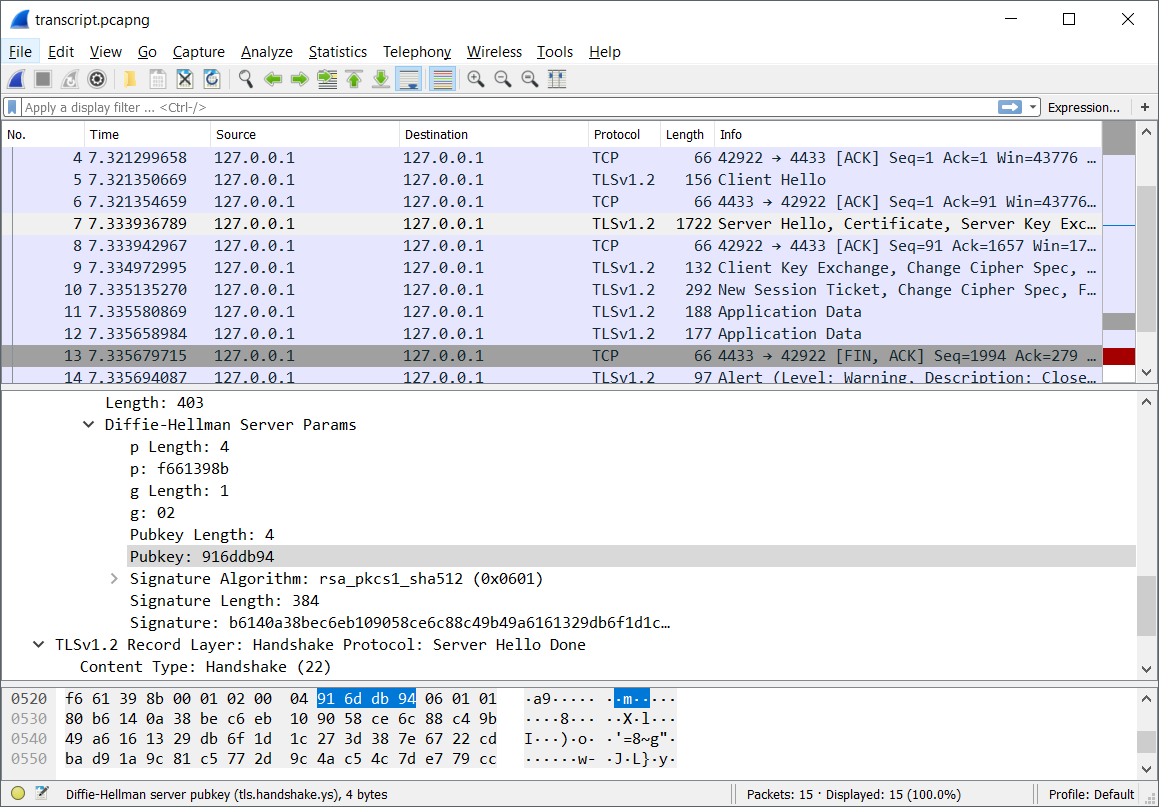
Looking at the Diffie-Hellman numbers in wireshark, we notice something very
interesting:
Those numbers look absolutely tiny! Diffie-Hellman’s security is based on the
difficulty of the Discrete Logarithm
problem. Ordinarily the p (prime) for DH is a 2048 bit number, here it’s
an abysmal 32 bits making it trivial to compute discrete logarithms
on. SageMath has several algorithms built in to
compute discrete logs so we wrote up a quick script to recover the client’s
secret number.
The client secret is then enough to compute the shared secret. This is known as
the pre-master secret in
TLS terms which is all wireshark needs to decrypt TLS traffic.
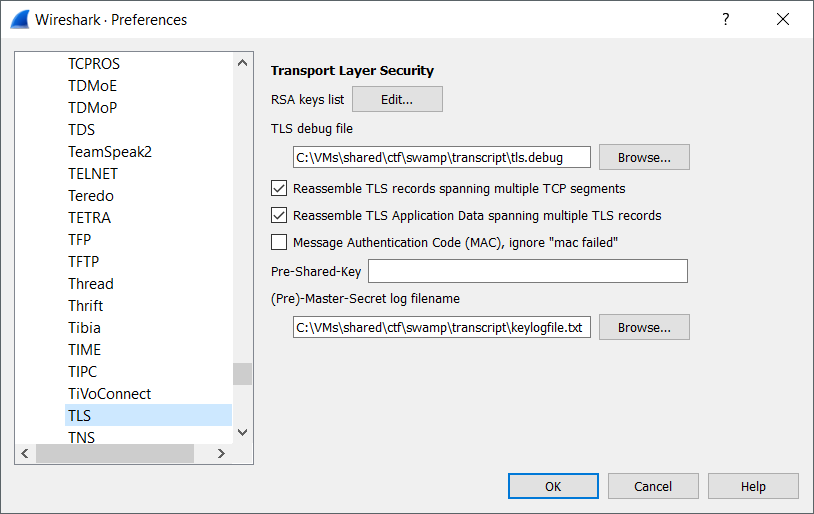
In order to let Wireshark utilize this, it needs a file mapping TLS sessions to
the master or pre-master secrets. So we made a file called keylogfile.txt
containing:
PMS stands for Pre-Master Secret and the giant number in the middle is the
client random, sent as part of the Client Hello packet which is what
wireshark uses to map the PMS to the right TLS session.
(Note: wireshark displays the timestamp and random bytes seperately if you
expand the Random portion in the TLS packet, the client random is the
timestamp and random bytes together.)
We set up Wireshark’s TLS protocol settings to use the log file:
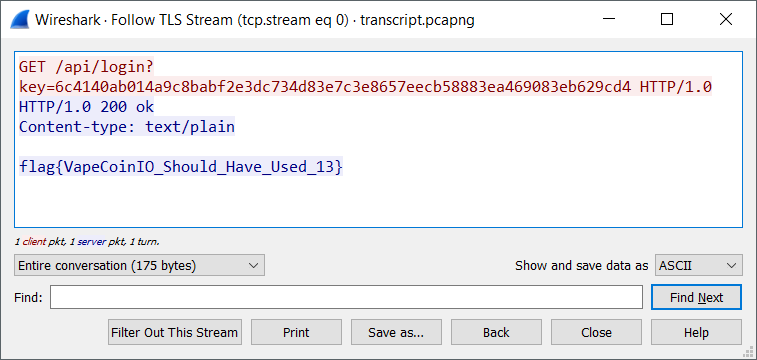
and boom, follow the TLS stream in Wireshark for the flag:







 With iClicker’s software, they can
conduct quizzes and export the answers for automatic grading.
With iClicker’s software, they can
conduct quizzes and export the answers for automatic grading.